World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
ما هو World Extractor؟
World Extractor هو إضافة Chrome تم تطويرها بواسطة r2media.in، والميزة الرئيسية لها هي "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV".
لقطات شاشة التمديد
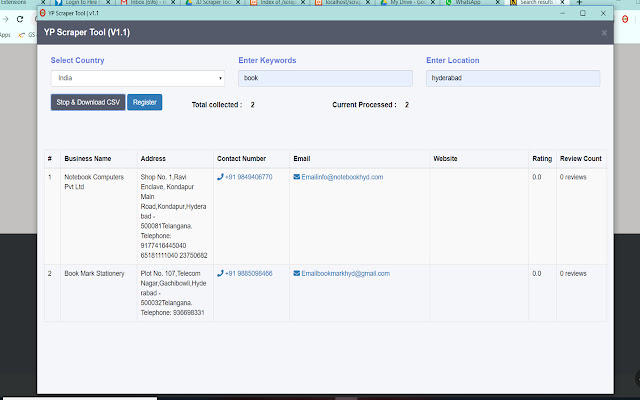

تحميل ملف CRX للإضافة World Extractor
قم بتنزيل ملفات الامتداد World Extractor بتنسيق crx ، وقم بتثبيت الامتدادات يدويًا في متصفح Chrome ، أو شارك ملفات crx مع الأصدقاء لتثبيت الامتدادات بسهولة.
تعليمات استخدام التمديد
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. معلومات أساسية عن التمديد
| الاسم |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| عنوان URL الرسمي | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| الوصف | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| حجم الملف | 2.03 MB |
| عدد التثبيتات | 172 |
| النسخة الحالية | 1.4 |
| آخر تحديث | 2020-03-28 |
| تاريخ النشر | 2020-03-28 |
| المطور | r2media.in |
| البريد الإلكتروني | [email protected] |
| نوع الدفع | free |
| عنوان صفحة المساعدة | https://api.whatsapp.com/send?phone=918804126048 |
| عنوان صفحة سياسة الخصوصية | http://r2media.in/Privacy-Policy |
| اللغات المدعومة | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























