World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
Co je World Extractor?
World Extractor je rozšíření Chrome vyvinuté r2media.in, a jeho hlavní funkcí je „Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV“.
Snímky obrazovky rozšíření
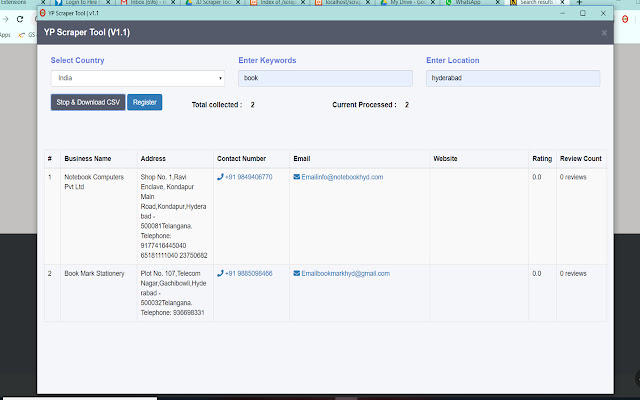

Stáhnout soubor CRX rozšíření World Extractor
Stáhněte si soubory rozšíření World Extractor ve formátu crx, ručně nainstalujte rozšíření Chrome do prohlížeče nebo sdílejte soubory crx s přáteli, abyste jednoduše nainstalovali rozšíření Chrome.
Pokyny pro Použití Rozšíření
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. Základní Informace o Rozšíření
| Název |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| Oficiální URL | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| Popis | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| Velikost souboru | 2.03 MB |
| Počet instalací | 172 |
| Aktuální Verze | 1.4 |
| Poslední Aktualizace | 2020-03-28 |
| Datum Vydání | 2020-03-28 |
| Vývojář | r2media.in |
| [email protected] | |
| Typ Platby | free |
| URL Stránky Nápovědy | https://api.whatsapp.com/send?phone=918804126048 |
| URL Stránky Zásad Ochrany Soukromí | http://r2media.in/Privacy-Policy |
| Podporované Jazyky | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























