World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
¿Qué es World Extractor?
World Extractor es una extensión de Chrome desarrollada por r2media.in, y su función principal es "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV".
Capturas de Pantalla de la Extensión
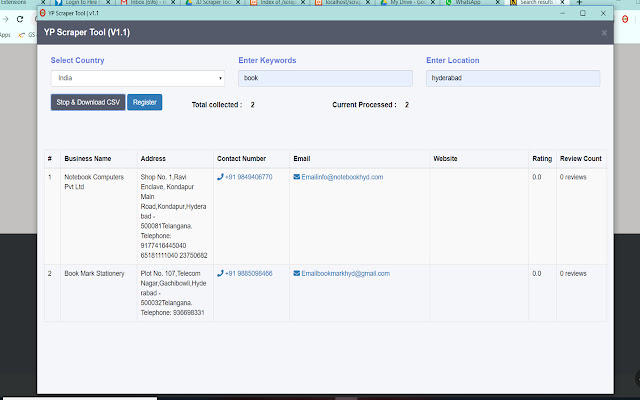

Descargar Archivo CRX de la Extensión World Extractor
Descarga archivos de extensión World Extractor en formato crx, instala manualmente las extensiones de Chrome en el navegador o comparte los archivos crx con amigos para instalar fácilmente las extensiones de Chrome.
Instrucciones de Uso de la Extensión
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. Información Básica de la Extensión
| Nombre |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| URL Oficial | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| Descripción | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| Tamaño del Archivo | 2.03 MB |
| Cantidad de Instalaciones | 172 |
| Versión Actual | 1.4 |
| Última Actualización | 2020-03-28 |
| Fecha de Publicación | 2020-03-28 |
| Desarrollador | r2media.in |
| Correo electrónico | [email protected] |
| Tipo de Pago | free |
| URL de la Página de Ayuda | https://api.whatsapp.com/send?phone=918804126048 |
| URL de la Página de Política de Privacidad | http://r2media.in/Privacy-Policy |
| Idiomas Soportados | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























