World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
World Extractor क्या है?
World Extractor r2media.in द्वारा विकसित एक क्रोम एक्सटेंशन है, और इसकी मुख्य विशेषता है "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV"।
एक्सटेंशन स्क्रीनशॉट्स
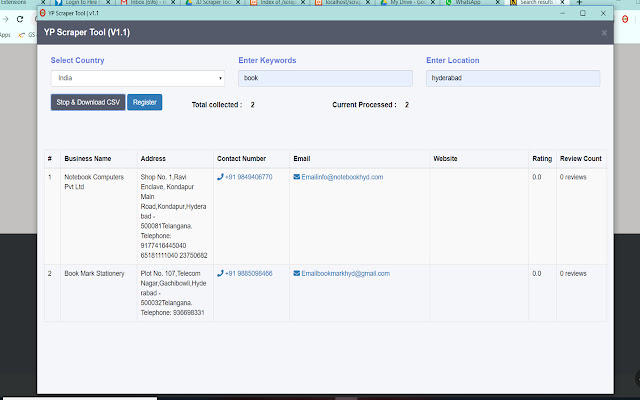

एक्सएक्स एक्सटेंशन CRX फ़ाइल डाउनलोड करें
crx प्रारूप में World Extractor एक्सटेंशन फ़ाइलें डाउनलोड करें, ब्राउज़र में क्रोम एक्सटेंशन को मैन्युअल रूप से स्थापित करें या दोस्तों के साथ crx फ़ाइलों को साझा करें ताकि क्रोम एक्सटेंशन को आसानी से स्थापित किया जा सके।
एक्सटेंशन उपयोग निर्देश
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. एक्सटेंशन की मूल जानकारी
| नाम |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| आधिकारिक URL | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| विवरण | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| फ़ाइल का आकार | 2.03 MB |
| स्थापना संख्या | 172 |
| वर्तमान संस्करण | 1.4 |
| अंतिम अपडेट | 2020-03-28 |
| प्रकाशन तिथि | 2020-03-28 |
| डेवलपर | r2media.in |
| ईमेल | [email protected] |
| भुगतान के प्रकार | free |
| सहायता पृष्ठ URL | https://api.whatsapp.com/send?phone=918804126048 |
| गोपनीयता नीति पृष्ठ URL | http://r2media.in/Privacy-Policy |
| समर्थित भाषाएँ | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























