World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
World Extractorとは何ですか?
World Extractorはr2media.inによって開発されたChromeの拡張機能で、その主な機能は「Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV」です。
拡張機能のスクリーンショット
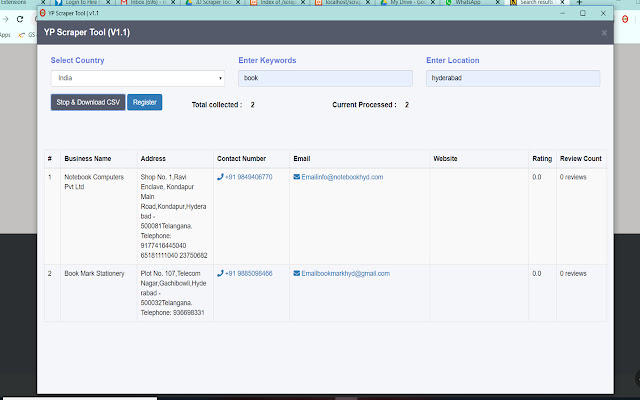

World Extractor拡張機能のCRXファイルをダウンロード
World Extractor拡張子のファイルをcrx形式でダウンロードし、ブラウザにChrome拡張機能を手動でインストールするか、crxファイルを友達と共有して簡単にChrome拡張機能をインストールします。
拡張機能の使用方法
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. 拡張機能の基本情報
| 名前 |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| 公式URL | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| 説明 | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| ファイルサイズ | 2.03 MB |
| インストール数 | 172 |
| 現在のバージョン | 1.4 |
| 最終更新日 | 2020-03-28 |
| 公開日 | 2020-03-28 |
| 開発者 | r2media.in |
| Eメール | [email protected] |
| 支払い方法 | free |
| ヘルプページのURL | https://api.whatsapp.com/send?phone=918804126048 |
| プライバシーポリシーページのURL | http://r2media.in/Privacy-Policy |
| 対応言語 | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























