World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
World Extractor란 무엇입니까?
World Extractor은(는) r2media.in에 의해 개발된 Chrome 확장 프로그램으로, 주요 기능은 "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV"입니다.
확장 프로그램 스크린샷
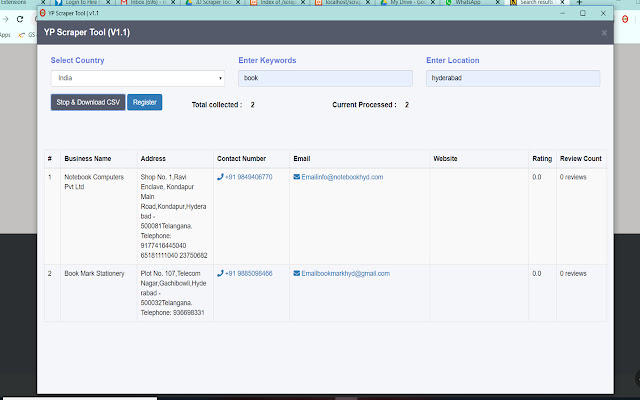

World Extractor 확장 프로그램 CRX 파일 다운로드
크롬 확장 프로그램을 crx 형식으로 다운로드하여 브라우저에 수동으로 설치하거나 crx 파일을 친구들과 공유하여 쉽게 크롬 확장 프로그램을 설치하세요.
확장 프로그램 사용 설명서
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. 확장 프로그램 기본 정보
| 이름 |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| 공식 URL | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| 설명 | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| 파일 크기 | 2.03 MB |
| 설치 횟수 | 172 |
| 현재 버전 | 1.4 |
| 최근 업데이트 | 2020-03-28 |
| 출시 날짜 | 2020-03-28 |
| 개발자 | r2media.in |
| 이메일 | [email protected] |
| 결제 유형 | free |
| 도움말 페이지 URL | https://api.whatsapp.com/send?phone=918804126048 |
| 개인정보 보호 정책 페이지 URL | http://r2media.in/Privacy-Policy |
| 지원되는 언어 | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























