World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
Co to jest World Extractor?
World Extractor to rozszerzenie Chrome opracowane przez r2media.in, a jego główną funkcją jest „Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV”.
Zrzuty ekranu rozszerzenia
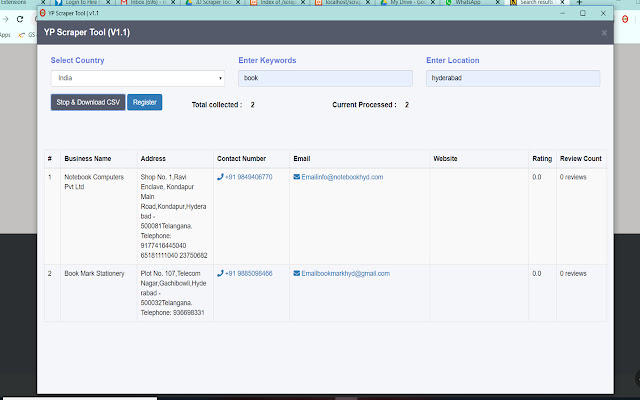

Pobierz plik CRX rozszerzenia World Extractor
Pobierz pliki rozszerzeń World Extractor w formacie crx, zainstaluj ręcznie rozszerzenia Chrome w przeglądarce lub udostępnij pliki crx znajomym, aby łatwo zainstalować rozszerzenia Chrome.
Instrukcja Użytkowania Rozszerzenia
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. Podstawowe informacje o rozszerzeniu
| Nazwa |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| Oficjalny URL | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| Opis | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| Rozmiar pliku | 2.03 MB |
| Liczba instalacji | 172 |
| Aktualna Wersja | 1.4 |
| Ostatnia Aktualizacja | 2020-03-28 |
| Data Publikacji | 2020-03-28 |
| Deweloper | r2media.in |
| [email protected] | |
| Typ Płatności | free |
| Adres URL Strony Pomocy | https://api.whatsapp.com/send?phone=918804126048 |
| Adres URL Strony Polityki Prywatności | http://r2media.in/Privacy-Policy |
| Obsługiwane Języki | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























