World Extractor
Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV
World Extractorคืออะไร?
World Extractor เป็นส่วนขยายของ Chrome ที่พัฒนาโดย r2media.in และคุณลักษณะหลักของมันคือ "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV"
ภาพหน้าจอของส่วนขยาย
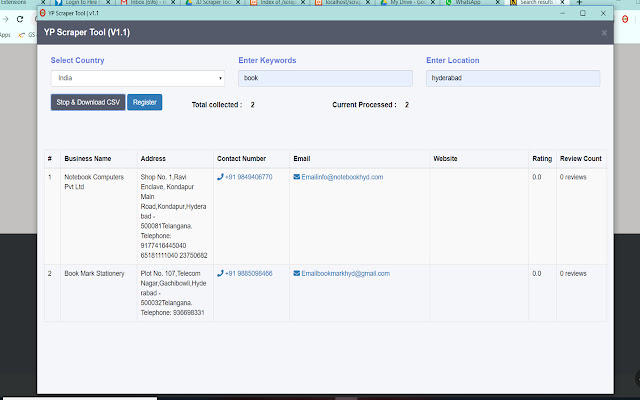

ดาวน์โหลดไฟล์ CRX ของส่วนขยาย World Extractor
ดาวน์โหลดไฟล์ส่วนขยาย World Extractor ในรูปแบบ crx และติดตั้งส่วนขยาย Chrome ด้วยตนเองในเบราว์เซอร์หรือแชร์ไฟล์ crx กับเพื่อนๆ เพื่อติดตั้งส่วนขยาย Chrome อย่างง่ายดาย
คำแนะนำในการใช้ส่วนขยาย
Extractor the information from yellowpages search results
Scraper extracts data out of search pages and into Microsoft Excel spreadsheets
The most extensive yellow pages Scraper tool to create actionable lists of leads
Use our yellow pages Scraper SEARCH data extractor tool to create actionable lists of leads for growth hacking. Quickly find useful data including - Name, Address, Contact Number, Email, website, Hours of operations, Modes of payment, Rating, Reviews, Directions, link and etc.. to build lists that really work!
Please install the corresponding Chrome extension as well to enable scraping of data. ข้อมูลพื้นฐานของส่วนขยาย
| ชื่อ |  World Extractor World Extractor |
| ID | akkehjobglbgbaifjnonmbookhekhgnd |
| URL อย่างเป็นทางการ | https://chrome.google.com/webstore/detail/world-extractor/akkehjobglbgbaifjnonmbookhekhgnd |
| คำอธิบาย | Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV |
| ขนาดไฟล์ | 2.03 MB |
| จำนวนการติดตั้ง | 172 |
| เวอร์ชันปัจจุบัน | 1.4 |
| อัปเดตครั้งล่าสุด | 2020-03-28 |
| วันที่เผยแพร่ | 2020-03-28 |
| ผู้พัฒนา | r2media.in |
| อีเมล | [email protected] |
| ประเภทการชำระเงิน | free |
| URL หน้าช่วยเหลือ | https://api.whatsapp.com/send?phone=918804126048 |
| URL หน้านโยบายความเป็นส่วนตัว | http://r2media.in/Privacy-Policy |
| ภาษาที่รองรับ | en |
| manifest.json | |
{
"update_url": "https:\/\/clients2.google.com\/service\/update2\/crx",
"name": "World Extractor",
"version": "1.4",
"description": "Scrape the information web search results Scraper extracts data out of search pages and into Microsoft Excel CSV",
"permissions": [
"activeTab",
"alarms",
"downloads",
"notifications",
"tabs",
"storage",
"*:\/\/r2media.in\/*"
],
"browser_action": {
"default_icon": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"default_title": "World Extractor"
},
"icons": {
"16": "images\/default_icon_16.png",
"24": "images\/default_icon_24.png",
"32": "images\/default_icon_32.png",
"48": "images\/default_icon_48.png",
"128": "images\/default_icon_128.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"background": {
"scripts": [
"libs\/jquery-3.1.1.min.js",
"js\/consts.js",
"js\/background.js"
]
},
"content_scripts": [
{
"matches": [
"*:\/\/*.indianyellowpages.com\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_in.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.guiamais.com.br\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_br.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.yellowpages.co.za\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sa.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.paginasamarillas.es\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_sp.js"
],
"run_at": "document_end"
},
{
"matches": [
"*:\/\/*.gelbeseiten.de\/*"
],
"js": [
"libs\/jquery-3.1.1.min.js",
"contentscript\/content_gr.js"
],
"run_at": "document_end"
}
],
"web_accessible_resources": [
"images\/*"
],
"manifest_version": 2
} | |























